什么是嵌入式向量数据库?一起深入Zvec的架构设计与实现
在大规模语言模型(LLM)应用蓬勃发展的今天,向量检索已成为语义搜索、RAG(检索增强生成)、推荐系统等场景的核心技术。传统的向量数据库通常以独立服务形式存在,需要额外部署和维护,这在一定程度上增加了系统的复杂性。Zvec 作为一款开源的嵌入式(in-process)向量数据库,为这一问题提供了优雅的解决方案。
Zvec 脱胎于阿里巴巴内部久经考验的向量检索引擎 Proxima,在继承其高性能向量索引能力的基础上,补齐了数据库层面的完整能力:持久化存储、Schema 管理和演进、标量过滤、崩溃恢复等。另外 Zvec 还针对开源的场景重新优化了向量索引和距离计算的算法实现,性能进一步提升。本文将深入剖析 Zvec 的整体架构和关键设计决策。
架构

Zvec 采用分层架构设计,自顶向下分为语言绑定层、数据库层、核心层和基础设施层。
最上层是语言绑定层,为 Python、Node.js、C、Rust、Go 等多种编程语言提供原生 SDK,使用者可以在自己熟悉的语言环境中直接调用 Zvec 的能力,无需关心底层实现。
数据库层是 Zvec 的核心业务逻辑所在。Collection 负责数据集合的生命周期管理,Segment 实现数据分段存储和 Writing/Persist 两阶段切换,SQLEngine 提供查询解析、执行计划生成和多段并行执行能力。在存储组件方面,WAL 保证写入的持久性和崩溃恢复能力,IDMap 维护用户主键到内部文档 ID 的映射,DeleteStore 基于 Roaring Bitmap 实现高效的软删除标记,ForwardStore 基于 Apache Arrow 的列式格式存储文档的原始字段数据。
核心层封装了向量检索的算法能力。Interface 对上层提供统一的索引创建、写入和检索接口,屏蔽不同算法的实现差异。目前支持 HNSW、IVF 和 Flat 等索引类型,分别满足不同场景的向量检索需求。
基础设施层为上层提供与平台无关的底层能力。SIMD 模块针对不同 CPU 架构自动选择最优的向量化指令集加速距离计算,KMeans 提供聚类训练支持,MMAP 和 BufferPool 分别实现内存映射和应用层缓冲池两种内存管理策略,ThreadPool 提供统一的并发执行框架,此外还包括 JSON 序列化、Hash 函数和 IO 文件读写等通用工具。
存储引擎
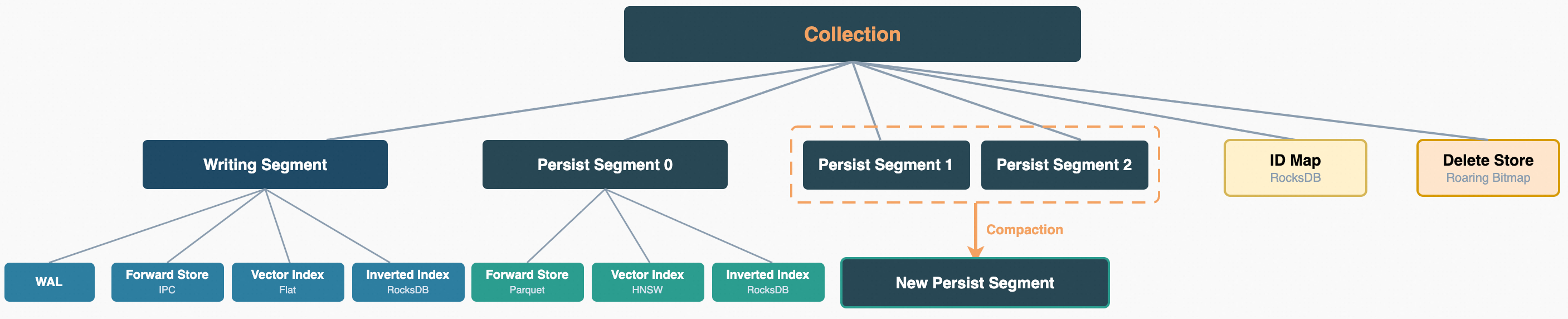
在 Zvec 中,Collection 是数据组织的基本单元,类似于关系数据库中的表。每个 Collection 拥有独立的 Schema 定义,内部由一个或多个 Segment 组成,并在 Collection 级别维护主键映射(IDMap)和删除标记(DeleteStore)。本节聚焦到单个 Segment 内部,逐一介绍三类存储组件和分段存储模式。每个 Segment 同时维护正排存储、向量索引和标量索引,分别负责文档原始数据的存取、高维向量的近似检索和标量字段的条件过滤。
正排存储
正排存储负责保存文档的原始字段数据,Zvec 持久化支持两种 Apache Arrow 生态的文件格式,后续便于和 pandas/pyarrow/datafusion/duckdb 等 Arrow 生态互通。默认使用 IPC 格式。
- IPC(也称 Feather/Arrow IPC)是 Arrow 的原生二进制格式,文件布局与内存中的 RecordBatch 完全一致,可通过 MMAP 实现零拷贝读取,省去反序列化开销,在中小规模数据的随机访问场景下延迟更低,适合高性能访问的场景。
- Parquet 是列式压缩格式,数据按 RowGroup 组织,支持列裁剪与谓词下推,适合存储量较大、需要节省磁盘空间的场景。
向量索引
Zvec Core 支持多种向量索引,通过插件机制,也支持进一步扩展支持其他索引类型。当前支持的索引类型如下:
- HNSW。分层可导航小世界图,最为流行的向量索引之一,使用类似跳表的思想,逐层快速逼近目标邻居所在的区域。内存使用较高,召回很高。
- HNSW-RabitqQ。RabitqQ 量化是一种新颖的量化技术,每一维 float32 只需要 1-9 bit来表示,利用位运算实现极速检索,并提供理论误差界限的保证,无须使用原始精度重新计算就能保证较高的召回。HNSW-RabitqQ 结合了 HNSW 索引和 RabitqQ 量化。
- FLAT。暴力计算,召回最高。
- IVFFLAT。基于聚类的索引方法,在构建阶段将每个向量分配到最近的聚类中心;在检索阶段先找到距查询向量最近的
nprobe个聚类中心,再在这些聚类内部进行精确搜索。召回较高。
更多的索引类型正在建设中,如DISKANN、SCANN,敬请期待。后续我们也将撰文详述我们在向量索引上做的优化工作。
标量索引
Zvec 支持的标量过滤操作包括:
- 比较操作:
=,!=,<,<=,>,>= - 模糊匹配:
LIKE - 集合操作:
CONTAIN_ALL,CONTAIN_ANY,NOT_CONTAIN_ALL,NOT_CONTAIN_ANY - NULL 检查:
IS NULL,IS NOT NULL - 前后缀匹配:
HAS_PREFIX,HAS_SUFFIX - 逻辑组合:
AND,OR
分析这些操作,既需要支持点查询,也需要支持范围查询。RocksDB 支持高效的点查询和范围查询:点查询通过MemTable和SSTable快速定位,结合布隆过滤器减少无效 IO;范围查询利用 SSTable 的有序性,通过多层合并迭代器高效输出结果。

目前 Zvec 的标量索引主要是倒排索引,它基于 RocksDB 构建,同一 Segment 内的所有索引列共享一个 RocksDB 实例,每个列通过独立的 Column Family 隔离数据。
在存储结构上,Key 是经过编码的字段值(Term),Value 是包含该值的文档 ID 集合。对于数值类型,编码时将原始字节转换为大端序并对符号位做翻转处理,使得编码后的字节序与数值的自然排序一致,从而可以直接利用 RocksDB 的有序迭代来支持范围查询。Value 端根据文档数量自适应选择存储格式:当匹配文档较少时,直接存储紧凑的 ID 列表;当文档数量超过阈值时,序列化为 Roaring Bitmap 以获得更好的压缩率和集合运算性能。
每个索引列维护多个 Column Family:正向 Term 索引用于等值和范围查询,反转 Term 索引用于后缀匹配(按需开启),数组长度索引用于数组字段的长度过滤(按需开启)。Writing Segment 持久化为 Persist Segment 时,还会生成统计性的 Range 索引和累积分布函数,用于后续查询时评估过滤条件的选择率。
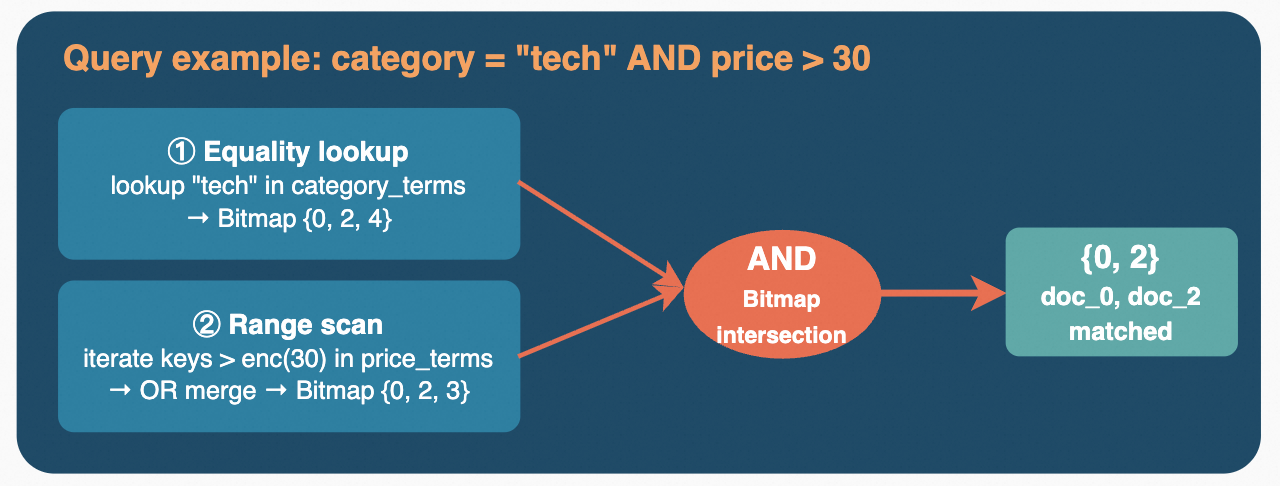
查询时,不同条件的结果通过 Roaring Bitmap 的交集、并集、取反等位运算高效组合,最终输出满足条件的文档集合。
段合并与标记删除
Zvec 的存储架构借鉴了 LSM-Tree 的核心思想:写入集中在内存中的 Writing Segment,积累到一定量后刷盘为只读的Persist Segment,最终通过合并将多个小段整理为大段。
在删除策略上,Zvec 采用标记删除(Soft Delete)而非物理删除,这个决策是由底层存储组件的特性所决定的。正排存储基于 Apache Arrow 的列式格式和 Parquet 文件,这类格式为批量追加和高效列式扫描而设计,本身不支持行级原地删除——要从一个 Parquet 文件中移除某一行,只能重写整个文件。向量索引的情况更为突出,以HNSW为例,HNSW 图结构中每个节点与其邻居通过双向边紧密连接,物理删除一个节点意味着要修复其所有邻居的连接关系,代价极高且可能破坏图的连通性和搜索质量。因此,Zvec 将删除操作转化为在 Roaring Bitmap 中设置一个标记位,查询时通过过滤器跳过已删除文档,写入路径不受任何影响。
真正的物理删除延迟到 Optimize 阶段的段合并中完成。系统会统计所有段中已删除文档的总比例,当超过 30% 时触发带清理的重建模式,将存活文档重新写入新段,已删除数据在这个过程中被自然丢弃。即使删除比例未达阈值,多个小段也会按容量上限分组合并为大段。
段合并的收益是综合性的。最直观的是查询变快了:合并前检索需要遍历多个小段再归并结果,合并后在一个段内就能完成,省去了跨段归并的开销。同时,向量索引会从写入期使用的 Flat 暴力搜索重建为 HNSW 图索引,检索复杂度从线性降到对数级别。倒排索引也会在合并后生成范围统计索引,让标量过滤有更优的查询路径可选。此外,合并过程会清理已删除的文档数据,真正释放磁盘空间。段数量的减少也意味着更少的文件句柄和 RocksDB 实例,降低系统资源占用。
写入流程
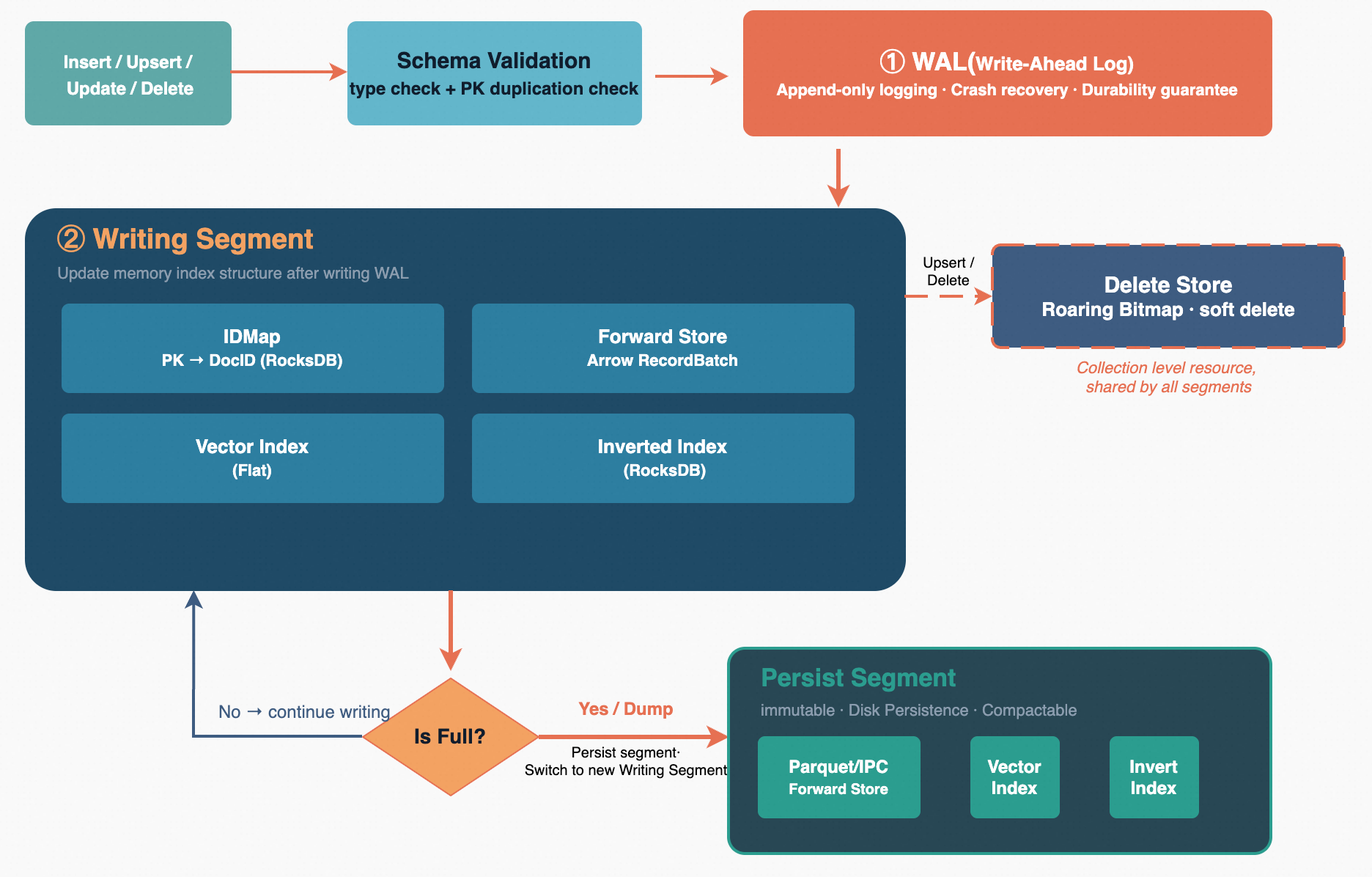
当用户调用 Insert、Upsert 或 Delete 接口时,请求首先经过 Schema 校验阶段,系统对每条文档执行字段类型检查和主键格式验证,确保数据符合 Collection 的结构定义。校验通过后,写入线程获取写锁进入互斥的写入临界区,保证同一时刻只有一个写入者在修改 Writing Segment。
写入每条文档前,系统会检查当前 Writing Segment 的文档数量是否已达到阈值。若未达到,文档直接写入当前Writing Segment:WAL 预写日志先行追加以保证持久性,随后 IDMap 记录主键到内部文档 ID 的映射,Forward Store 以 Arrow 列式格式存储原始字段值,向量索引和倒排索引同步实时更新。对于 Upsert 操作,系统通过 IDMap 检测主键是否已存在,若已存在则在 DeleteStore 的 Roaring Bitmap 中标记旧文档为删除,再插入新文档,从而实现幂等写入语义。
当文档数达到阈值时,触发段切换。系统首先将当前 Writing Segment 的内存数据刷写为 Parquet 或 IPC 磁盘文件,然后将该段注册到 SegmentManager 中成为只读的 Persist Segment。紧接着创建一个全新的空段作为新的 Writing Segment,其起始文档 ID 衔接上一段的末尾。最后通过 VersionManager 完成原子性的版本切换——将旧段元数据纳入已持久化列表,将新段设为当前写入段,一次性提交并落盘。整个切换过程对外部查询完全透明,查询会同时搜索所有 Persist Segments 和当前 Writing Segment,不会出现数据不可见的窗口期。
查询流程
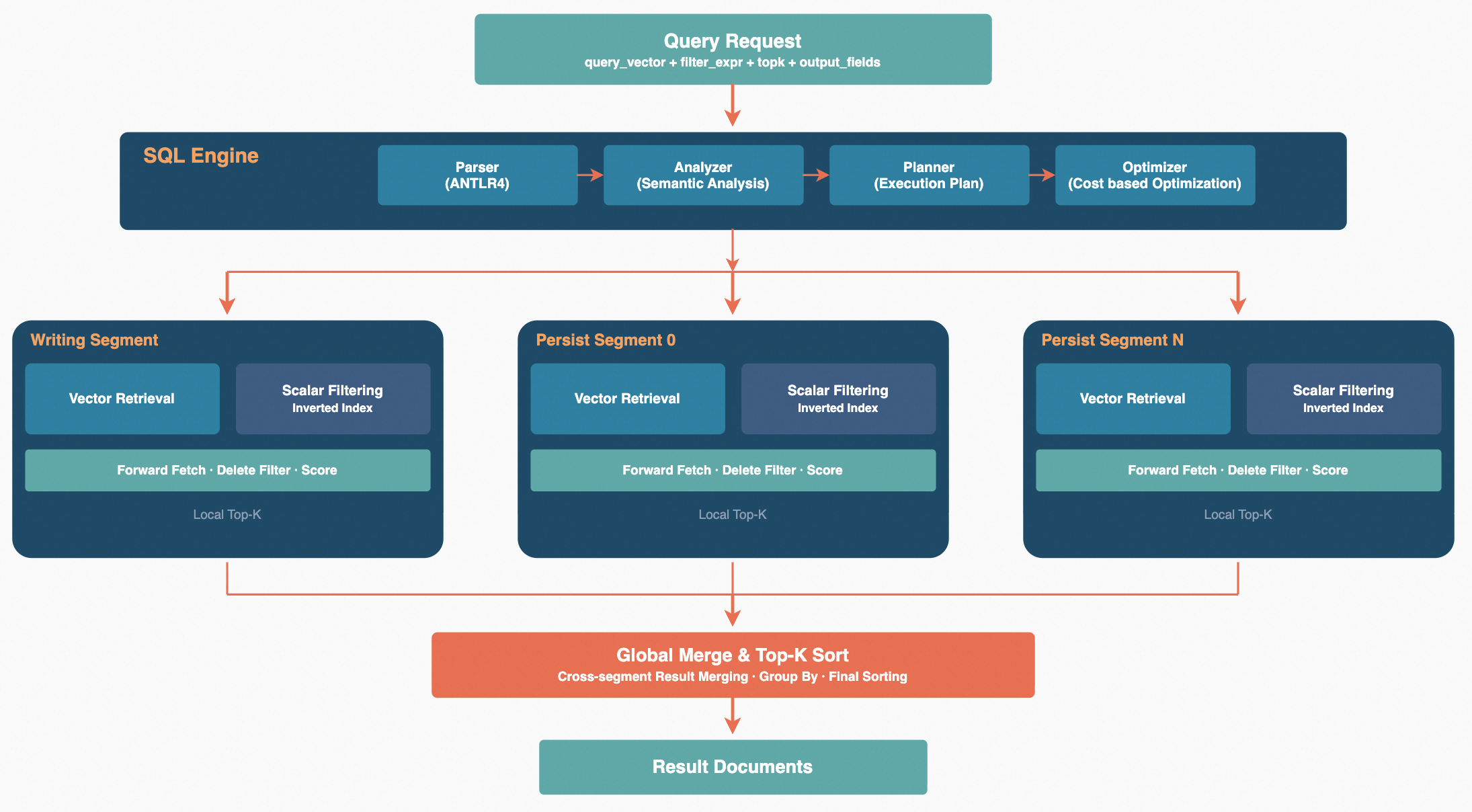
Zvec 的查询引擎构建在 Apache Arrow Acero 流式执行框架之上,采用 Parse → Analyze → Plan → Execute 四阶段流水线。查询请求首先经过 Parser 将过滤表达式解析为语法树,再由 Analyzer 根据 Schema 将条件拆分为三类:向量检索条件、倒排过滤条件和正排过滤条件。Planner 根据分析结果为每个 Segment 确定最佳的执行策略。多 Segment 场景下,各段的查询计划通过线程池并行执行,结果流式汇聚后经全局排序和 TopN 截断得到最终输出。整个过程基于 Arrow RecordBatch 列式批次传递,支持向量化计算,减少内存拷贝开销。
检索优化
向量检索通常需要结合标量过滤条件(如 category = 'tech' AND price < 100),业界有两种主流的过滤策略。
- 后过滤是最简单的方案:先完成 ANN 检索取回 TopK 候选,再逐一检查标量条件,丢弃不满足的文档。这种方式实现简单,但当过滤条件选择性较高时,大量召回结果被淘汰,最终返回数量远少于 K,甚至为空。
- 前过滤则相反:先通过倒排索引或正排扫描计算出满足标量条件的文档集合,再将该集合作为候选范围执行向量检索。前过滤保证结果数量准确,但当候选集很大时,需要对向量索引做受限搜索,可能影响检索效率。
Zvec 的优化器总体上基于代价的模型进行决策,根据检索条件的过滤比(过滤比定义为不满足过滤条件的文档数除以总文档数)采用不同的检索策略。
- 在过滤比非常高时(默认大于90%),采用前过滤方案。先根据过滤条件计算 bitmap,得到满足条件的 doc 列表,然后对这些 doc 做暴力计算。
- 其他情况下,采用边检索边过滤的策略。在向量索引遍历过程中,每访问一个候选文档就实时判断其是否满足过滤条件,仅在满足过滤条件时才会加入结果集中。虽然同样采用边检索边过滤的执行策略,但在不同的过滤条件下也会有不同的选择。
- 在过滤比适中时,在执行向量检索前,根据过滤条件计算bitmap,在向量检索中只需要查询 bitmap。
- 在过滤比非常低时(默认小于10%),计算 bitmap 也会引入额外的开销,此时改为直接读取正排数据判断是否满足过滤条件。
Zvec 在计算 bitmap 时,既支持倒排索引,也支持通过 arrow 的向量化执行引擎计算正排字段的 bitmap。
内存管理
Zvec 支持多种内存管理模式,满足不同场景的需求。
MMAP 模式将磁盘文件映射到进程的虚拟地址空间,页面的加载和淘汰完全交由操作系统的 Page Cache 管理。应用层无需关心缓存逻辑,访问磁盘数据如同访问内存,实现简单且开销低。这种方式适合内存相对充裕的场景,但缺点在于淘汰策略由操作系统决定,应用层无法根据自身的访问模式做精细化控制,在内存不足时性能明显下降。
Buffer Pool 模式则在应用层维护一个带 LRU 淘汰策略的缓冲池,对正排数据和向量索引提供统一的缓存管理。数据按细粒度的块进行缓存,访问时先查缓冲池,命中则直接返回,未命中再从磁盘加载。缓存项关联了文件标识和修改时间,Segment Compaction 导致底层文件变化后缓存自动失效,保证数据一致性。当内存达到预设上限时,优先淘汰最久未访问的数据块。这种方式适合数据量远超可用内存的大规模场景,让应用在有限的内存预算下依然维持稳定的访问性能。
总结
回顾 Zvec 的整体设计,有几个关键决策值得特别关注。
- 嵌入式架构的选择消除了网络通信开销和额外的运维负担,既能保护数据隐私,又能做到低延迟响应。
- Segment 分段存储借鉴了 LSM-Tree 数据库的思想,将写入集中在内存中的 Writing Segment,通过后台合并将小段合成大段。这种设计能够达到低延迟写入和高性能查询。
- Arrow + Parquet 的组合,为正排存储带来了极致的列存效率与广泛的生态兼容支持。
- 软删除 + Compaction 的删除策略避免了对索引结构的实时修改,将代价高昂的物理删除集中在后台操作中完成。
Zvec 目前已经具备了嵌入式向量数据库的基本能力,可以在不引入额外服务依赖的前提下满足常见的向量检索需求。我们将在功能、性能、生态各方面持续迭代,也欢迎社区的反馈和参与。