Demystifying Embedded Vector Databases: A Tour of Zvec's Architecture
With the rapid growth of large language model (LLM) applications, vector search has become a core technology powering semantic search, RAG (Retrieval-Augmented Generation), recommendation systems, and similar use cases. Traditional vector databases typically exist as standalone services that require additional deployment and maintenance, increasing overall system complexity. Zvec, an open-source embedded (in-process) vector database, provides an elegant solution to this problem.
Zvec originated from Proxima, a battle-tested vector search engine used internally at Alibaba. While inheriting Proxima's high-performance vector indexing capabilities, Zvec adds the full set of database-level features: persistent storage, schema management and evolution, scalar filtering, crash recovery, and more. In addition, Zvec has re-optimized its vector index and distance computation algorithms specifically for the open-source scenario, further improving performance. This article provides an in-depth analysis of Zvec's overall architecture and key design decisions.
Architecture

Zvec adopts a layered architecture, divided from top to bottom into the Language Bindings layer, the Database layer, the Core layer, and the Infrastructure layer.
The topmost layer is the Language Bindings layer, which provides native SDKs for multiple programming languages including Python, Node.js, C, Rust, and Go. Users can invoke Zvec's capabilities directly in their preferred language environment without worrying about the underlying implementation.
The Database layer is where Zvec's core business logic resides. Collection manages the lifecycle of data collections; Segment implements segmented data storage and the two-phase Writing/Persist switching; SQLEngine provides query parsing, execution plan generation, and multi-segment parallel execution capabilities. Among the storage components, WAL ensures write durability and crash recovery; IDMap maintains the mapping from user primary keys to internal document IDs; DeleteStore implements efficient soft-delete marking based on Roaring Bitmap; and ForwardStore stores raw document field data in Apache Arrow's columnar format.
The Core layer encapsulates the algorithmic capabilities for vector search. Interface exposes a unified API for index creation, insertion, and search to the upper layers, abstracting away the implementation differences between various algorithms. Currently supported index types include HNSW, IVF, and Flat, each addressing vector search requirements in different scenarios.
The Infrastructure layer provides platform-independent low-level capabilities to the upper layers. The SIMD module automatically selects the optimal vectorized instruction set for the target CPU architecture to accelerate distance computation; KMeans provides clustering training support; MMAP and BufferPool implement two memory management strategies — memory-mapped files and application-level buffer pooling, respectively; ThreadPool provides a unified concurrent execution framework. Additional utilities include JSON serialization, hash functions, and file I/O operations.
Storage Engine
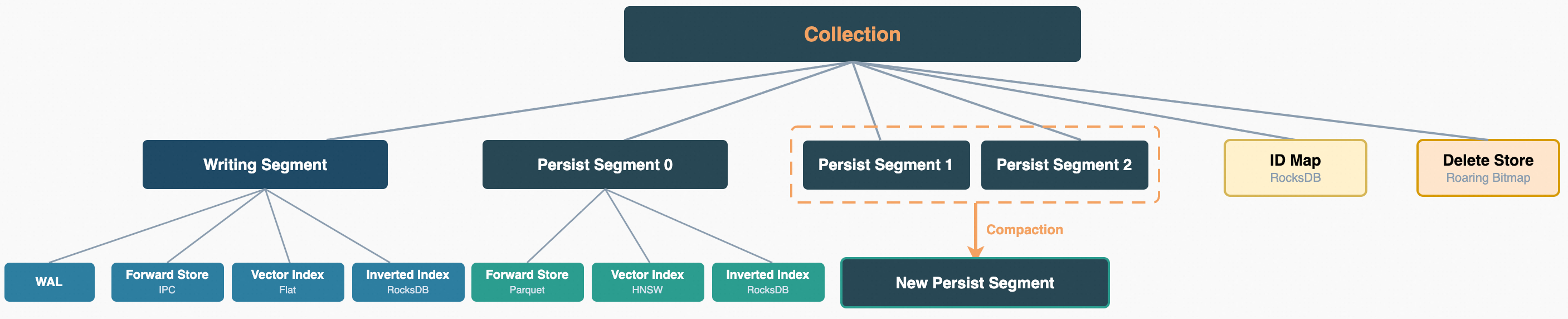
In Zvec, a Collection is the basic unit of data organization, analogous to a table in a relational database. Each Collection has its own schema definition and is internally composed of one or more Segments. Primary key mapping (IDMap) and deletion markers (DeleteStore) are maintained at the Collection level. This section focuses on the internals of a single Segment, covering the three types of storage components and the segmented storage model. Each Segment simultaneously maintains a forward store, a vector index, and a scalar index, responsible for raw document data access, approximate nearest-neighbor search over high-dimensional vectors, and conditional filtering on scalar fields, respectively.
Forward Store
The forward store is responsible for persisting the raw field data of documents. Zvec supports two file formats from the Apache Arrow ecosystem for persistence, facilitating interoperability with Arrow ecosystem tools such as pandas, pyarrow, datafusion, and duckdb. The default format is IPC.
- IPC (also known as Feather/Arrow IPC) is Arrow's native binary format. Its file layout is identical to the in-memory RecordBatch representation, enabling zero-copy reads via MMAP and eliminating deserialization overhead. It offers lower latency for random access on small-to-medium scale data and is suitable for high-performance access scenarios.
- Parquet is a columnar compressed format where data is organized by RowGroup, supporting column pruning and predicate pushdown. It is suitable for scenarios with larger data volumes where disk space savings are needed.
Vector Index
Zvec Core supports multiple vector index types and, through a plugin mechanism, can be further extended to support additional index types. The currently supported index types are as follows:
- HNSW. Hierarchical Navigable Small World graph, one of the most popular vector indexes. It uses a skip-list-like approach to quickly converge toward the region containing the target neighbors, layer by layer. Memory usage is relatively high; recall is very high.
- HNSW-RabitqQ. RabitqQ quantization is a novel quantization technique that represents each float32 dimension with only 1–9 bits, leveraging bit operations for extremely fast search while providing theoretical error bound guarantees — achieving high recall without recomputing with full-precision vectors. HNSW-RabitqQ combines the HNSW index with RabitqQ quantization.
- FLAT. Brute-force search with the highest recall.
- IVFFLAT. A clustering-based index method that assigns each vector to the nearest cluster centroid during the build phase. During search, the
nprobecluster centroids closest to the query vector are identified first, and then exact search is performed within those clusters. Recall is relatively high.
Additional index types such as DiskANN and ScaNN are under development — stay tuned. We will also publish dedicated articles detailing our optimization work on vector indexing.
Scalar Index
The scalar filtering operations supported by Zvec include:
- Comparison operations:
=,!=,<,<=,>,>= - Fuzzy matching:
LIKE - Set operations:
CONTAIN_ALL,CONTAIN_ANY,NOT_CONTAIN_ALL,NOT_CONTAIN_ANY - NULL checks:
IS NULL,IS NOT NULL - Prefix/suffix matching:
HAS_PREFIX,HAS_SUFFIX - Logical combinations:
AND,OR
These operations require support for both point queries and range queries. RocksDB supports efficient point queries and range queries: point queries quickly locate data through MemTable and SSTable lookups combined with Bloom filters to reduce unnecessary I/O; range queries exploit the sorted nature of SSTables, efficiently producing results through multi-level merge iterators.

Currently, Zvec's scalar index is primarily an inverted index built on top of RocksDB. All indexed columns within the same Segment share a single RocksDB instance, with each column isolated via its own Column Family.
In terms of storage layout, the Key is the encoded field value (term), and the Value is the set of document IDs containing that value. For numeric types, the encoding converts raw bytes to big-endian order and flips the sign bit, ensuring that the byte ordering of the encoded values matches the natural numeric ordering. This allows range queries to be directly supported through RocksDB's ordered iteration. On the Value side, the storage format is adaptively selected based on the number of matching documents: when there are few matching documents, a compact ID list is stored directly; when the document count exceeds a threshold, the list is serialized as a Roaring Bitmap for better compression ratios and set operation performance.
Each indexed column maintains multiple Column Families: a forward term index for equality and range queries, a reverse term index for suffix matching (enabled on demand), and an array length index for length filtering on array fields (enabled on demand). When a Writing Segment is persisted into a Persist Segment, statistical range indexes and cumulative distribution functions (CDFs) are also generated, which are used to estimate the selectivity of filter conditions during subsequent queries.
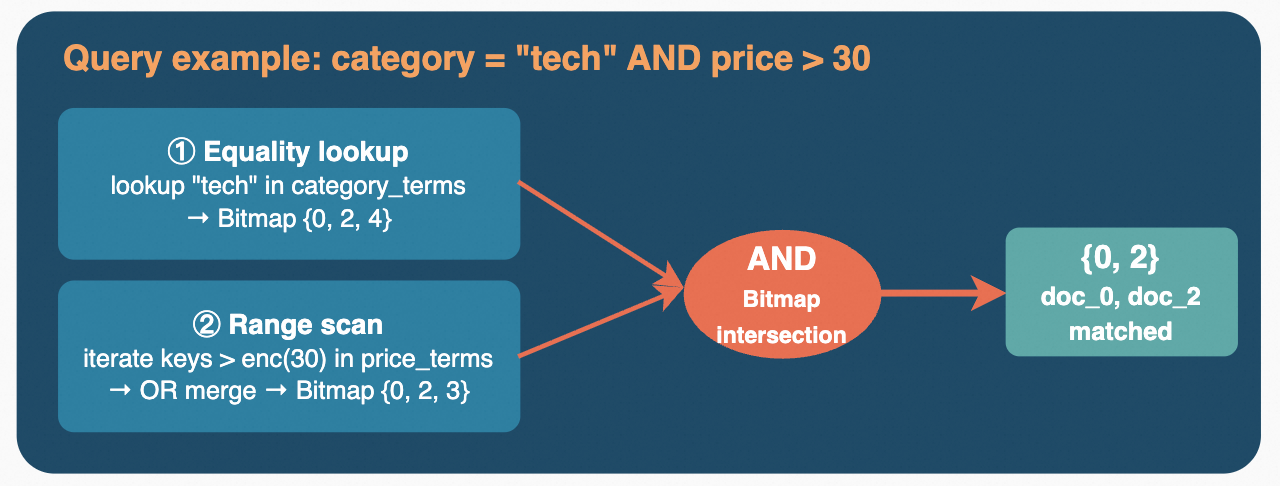
At query time, the results from different conditions are efficiently combined through Roaring Bitmap set operations — intersection, union, complement, and other bitwise operations — to produce the final set of matching documents.
Segment Compaction and Soft Delete
Zvec's storage architecture draws from the core ideas of LSM-Trees: writes are concentrated in an in-memory Writing Segment; once a sufficient amount of data accumulates, it is flushed to disk as a read-only Persist Segment; and eventually, multiple small segments are merged into larger ones through compaction.
Regarding deletion strategy, Zvec employs soft delete rather than physical delete — a decision driven by the characteristics of the underlying storage components. The forward store is based on Apache Arrow's columnar format and Parquet files — formats designed for batch appends and efficient columnar scans that do not inherently support row-level in-place deletion. Removing a single row from a Parquet file requires rewriting the entire file. The situation is even more pronounced for vector indexes: taking HNSW as an example, each node in the HNSW graph is tightly connected to its neighbors via bidirectional edges. Physically deleting a node requires repairing all its neighbors' connections, which is extremely costly and may compromise the graph's connectivity and search quality. Therefore, Zvec converts delete operations into setting a marker bit in a Roaring Bitmap. At query time, deleted documents are skipped via a filter, and the write path is not affected in any way.
Actual physical deletion is deferred to segment compaction during the Optimize phase. The system tracks the overall proportion of deleted documents across all segments. When this proportion exceeds 30%, a rebuild-with-cleanup mode is triggered: surviving documents are rewritten into new segments, and deleted data is naturally discarded in the process. Even when the deletion ratio does not reach the threshold, multiple small segments are still grouped and merged into larger segments up to a capacity limit.
The benefits of segment compaction are comprehensive. The most immediate benefit is improved query performance: before compaction, a search must traverse multiple small segments and merge results; after compaction, it can be completed within a single segment, eliminating the overhead of cross-segment merging. At the same time, vector indexes are rebuilt from the Flat brute-force search used during the writing phase to HNSW graph indexes, reducing search complexity from linear to logarithmic. Inverted indexes also generate range statistical indexes after compaction, providing more optimal query paths for scalar filtering. Furthermore, the compaction process cleans up deleted document data, truly reclaiming disk space. The reduction in segment count also means fewer file handles and RocksDB instances, lowering system resource consumption.
Write Path
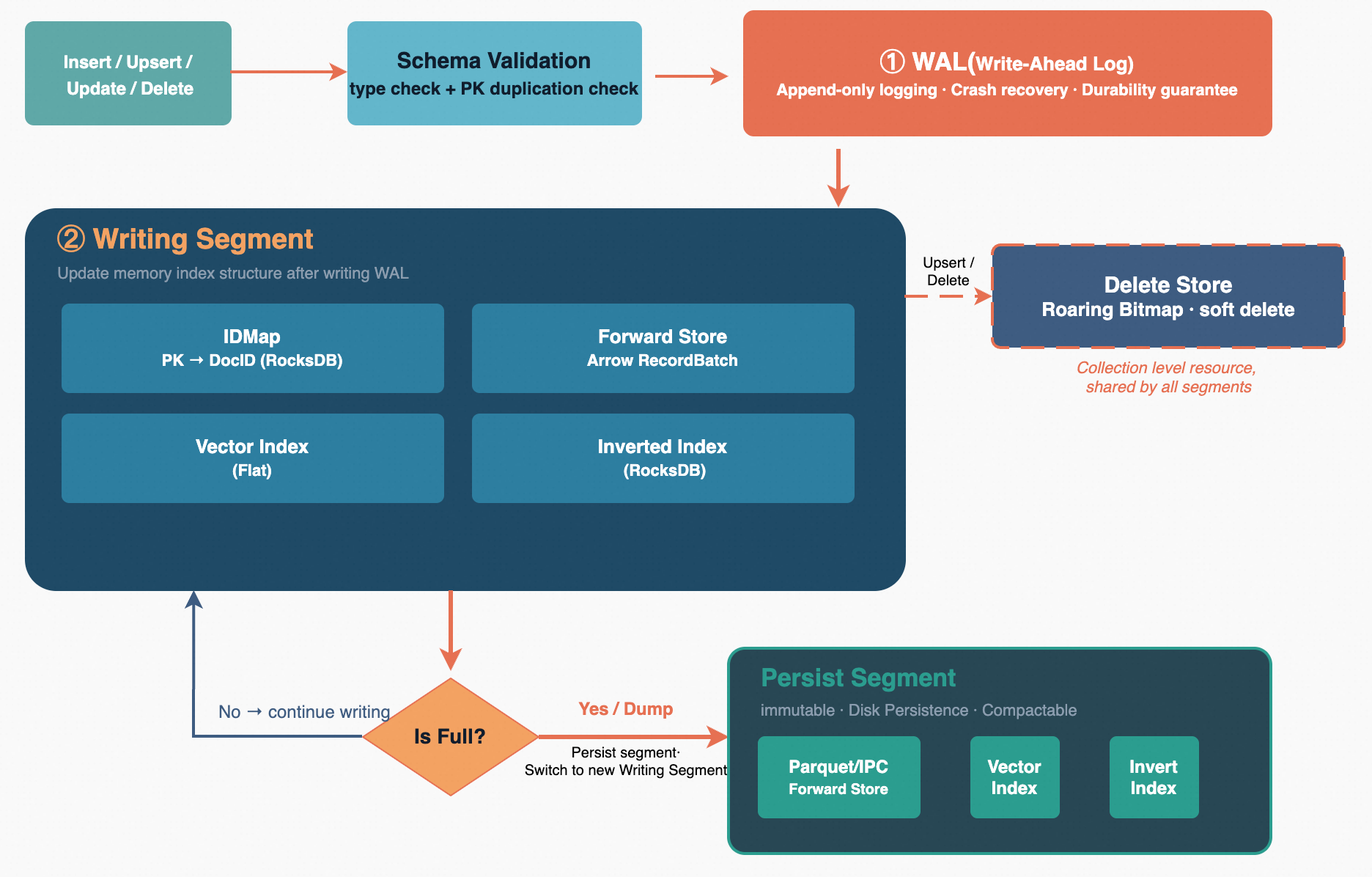
When a user invokes the Insert, Upsert, or Delete API, the request first passes through the schema validation stage, where the system performs field type checking and primary key format verification on each document to ensure the data conforms to the Collection's schema definition. After validation, the write thread acquires a write lock to enter an exclusive write critical section, guaranteeing that only one writer is modifying the Writing Segment at any given time.
Before writing each document, the system checks whether the current Writing Segment's document count has reached the threshold. If not, the document is written directly to the current Writing Segment: the WAL (write-ahead log) appends the entry first to ensure durability; then IDMap records the mapping from the primary key to the internal document ID; ForwardStore stores the raw field values in Arrow columnar format; and the vector index and inverted index are updated synchronously in real time. For Upsert operations, the system checks via IDMap whether the primary key already exists. If it does, the old document is marked as deleted in DeleteStore's Roaring Bitmap before inserting the new document, thus achieving idempotent write semantics.
When the document count reaches the threshold, a segment switch is triggered. The system first flushes the current Writing Segment's in-memory data to disk as a Parquet or IPC file, then registers that segment with the SegmentManager as a read-only Persist Segment. A brand-new empty segment is then created as the new Writing Segment, with its starting document ID continuing from the end of the previous segment. Finally, the VersionManager performs an atomic version switch — incorporating the old segment's metadata into the persisted list, setting the new segment as the current write target, and committing everything to disk in a single operation. The entire switch is completely transparent to external queries: queries simultaneously search all Persist Segments and the current Writing Segment, with no window during which data becomes invisible.
Query Path
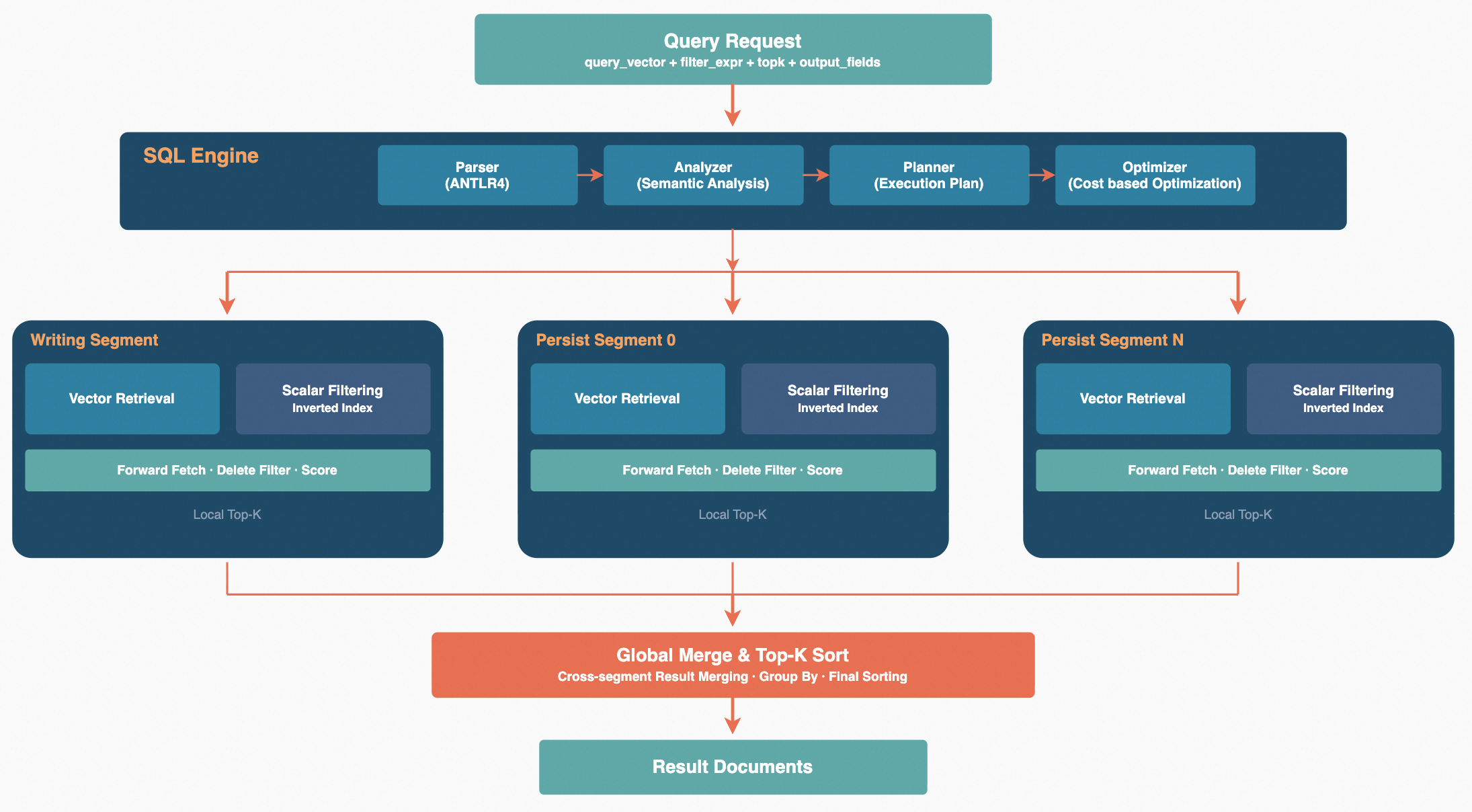
Zvec's query engine is built on top of the Apache Arrow Acero streaming execution framework and follows a four-stage pipeline: Parse -> Analyze -> Plan -> Execute. A query request first passes through the Parser, which parses filter expressions into a syntax tree. The Analyzer then splits the conditions based on the schema into three categories: vector search conditions, inverted filter conditions, and forward filter conditions. The Planner determines the optimal execution strategy for each Segment based on the analysis results. In a multi-Segment scenario, query plans for each segment are executed in parallel via a thread pool, and results are merged in a streaming fashion, followed by global sorting and TopN truncation to produce the final output. The entire process passes data as Arrow RecordBatch columnar batches, supporting vectorized computation and reducing memory copy overhead.
Search Optimization
Vector search typically needs to be combined with scalar filter conditions (e.g., category = 'tech' AND price < 100). There are two mainstream filtering strategies in the industry.
- Post-filtering is the simplest approach: first complete the ANN search to retrieve the TopK candidates, then check the scalar conditions one by one and discard documents that do not match. This approach is simple to implement, but when the filter conditions have high selectivity, a large portion of the recall results are eliminated, and the final returned count can be far fewer than K, or even zero.
- Pre-filtering is the opposite: first compute the set of documents satisfying the scalar conditions via the inverted index or forward scan, then perform vector search within that candidate set. Pre-filtering guarantees an accurate result count, but when the candidate set is large, the vector index must perform a constrained search, which may affect search efficiency.
Zvec's optimizer makes decisions based on a cost model, adopting different search strategies according to the filter ratio of the search conditions. The filter ratio is defined as the number of documents not satisfying the filter condition divided by the total document count.
- When the filter ratio is very high (default > 90%), the pre-filtering approach is used. A bitmap is first computed based on the filter conditions to obtain the list of documents satisfying the conditions, and then brute-force search is performed on those documents.
- In other cases, an inline filtering (filter-while-search) strategy is adopted. During vector index traversal, each candidate document is checked in real time against the filter conditions, and only documents satisfying the conditions are added to the result set. Although the same filter-while-search execution strategy is used, different choices are made under different filter conditions:
- When the filter ratio is moderate, a bitmap is computed based on the filter conditions before executing the vector search, and during vector search only the bitmap needs to be queried.
- When the filter ratio is very low (default < 10%), computing the bitmap itself introduces additional overhead. In this case, the system reads the forward store data directly to determine whether each document satisfies the filter conditions.
When computing bitmaps, Zvec supports both the inverted index and Arrow's vectorized execution engine for computing bitmaps over forward store fields.
Memory Management
Zvec supports multiple memory management modes to meet the needs of different scenarios.
MMAP mode maps disk files into the process's virtual address space, with page loading and eviction entirely managed by the operating system's Page Cache. The application layer does not need to handle caching logic — accessing disk data is as straightforward as accessing memory. It is simple to implement and incurs low overhead. This approach is suitable for scenarios with relatively abundant memory, but the downside is that the eviction strategy is determined by the operating system. The application layer cannot perform fine-grained control based on its own access patterns, and performance degrades noticeably under memory pressure.
Buffer Pool mode maintains an application-level buffer pool with an LRU eviction policy, providing unified cache management for forward store data and vector indexes. Data is cached at a fine-grained block level: on access, the buffer pool is checked first — a hit returns the data directly, while a miss triggers a disk load. Cache entries are associated with file identifiers and modification timestamps; when Segment Compaction causes underlying files to change, the cache is automatically invalidated to ensure data consistency. When memory reaches a preset limit, the least recently accessed data blocks are evicted first. This approach is suitable for large-scale scenarios where data volume far exceeds available memory, allowing the application to maintain stable access performance within a limited memory budget.
Summary
Looking back at Zvec's overall design, several key decisions deserve special attention:
- The choice of an embedded architecture eliminates network communication overhead and additional operational burden, while protecting data privacy and achieving low-latency responses.
- Segment-based storage draws from LSM-Tree database design principles, concentrating writes in an in-memory Writing Segment and merging small segments into larger ones through background compaction. This design achieves both low-latency writes and high-performance queries.
- The combination of Arrow + Parquet brings exceptional columnar storage efficiency and broad ecosystem compatibility to the forward store.
- The soft delete + compaction deletion strategy avoids real-time modifications to index structures, deferring costly physical deletion to background operations.
Zvec currently provides the fundamental capabilities of an embedded vector database, meeting common vector search requirements without introducing additional service dependencies. We will continue to iterate on functionality, performance, and ecosystem integration, and we welcome community feedback and contributions.